西雅图房价预测项目
项目仓库:🔗 GitHub - KingCountyHousePrediction 技术栈:Python 3.11 · TensorFlow · XGBoost · LightGBM · CatBoost · scikit-learn
前言¶
"Location, Location, Location." —— 这是房地产行业最经典的一句话。
但如果让一个机器学习模型来理解这句话,需要多少工程量?
本文记录了我在西雅图 King County 房价预测项目中,从一个简单的两层 MLP 出发,经过三个迭代阶段,最终构建出一套五模型 Stacking 集成方案的完整过程。不是调参炼丹流水账,而是一次围绕偏差-方差-噪声分解的系统性建模实践。
如果你正在做表格数据回归任务,或者想了解 Stacking 集成到底怎么设计,希望这篇文章能给你一些实用参考。
一、问题与数据¶
1.1 任务定义¶
基于 King County(西雅图大都会区)2014–2015 年的 10,000 条真实房屋交易记录,预测房屋成交价格。14 个特征涵盖面积、卧室数、评分、建造年份、经纬度等维度。
1.2 数据初探¶
拿到数据的第一件事,当然是看分布。
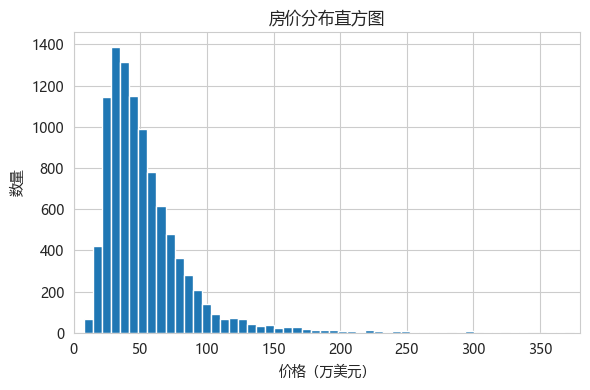
发现一:价格分布严重右偏。大部分房屋集中在 20-60 万美元区间,但少量豪宅价格超过 200 万。这种长尾分布如果直接用 MSE 训练,高价房会对损失函数产生不成比例的影响。
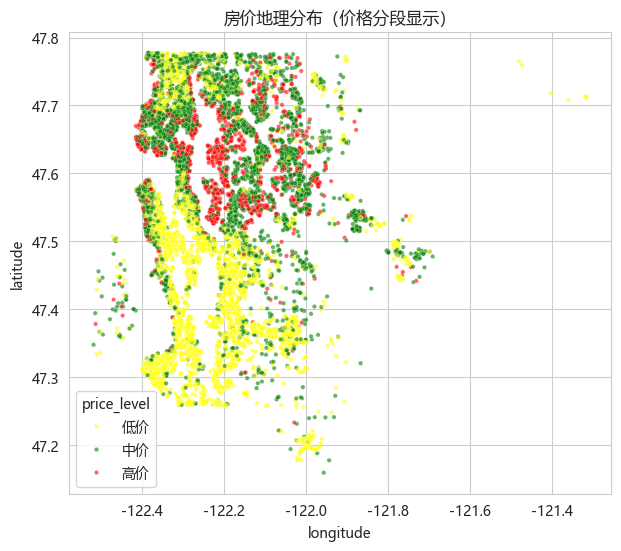
发现二:房价存在极强的空间聚集效应。地图上可以清晰看到,市中心和湖景区域(红色高价点)与郊区(蓝色低价点)之间有明确的地理分界线。这意味着"位置"不仅仅是两个坐标数字,而是一种需要被建模的空间结构。
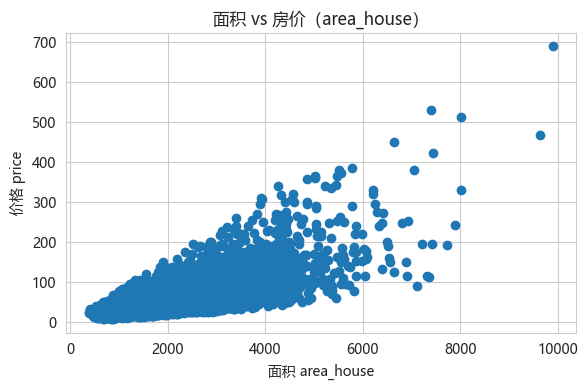
发现三:面积与价格呈非线性关系,且散点图呈现明显的异方差性(漏斗形扩散)—— 房屋面积越大,价格波动范围越大。
1.3 数据质量检查¶
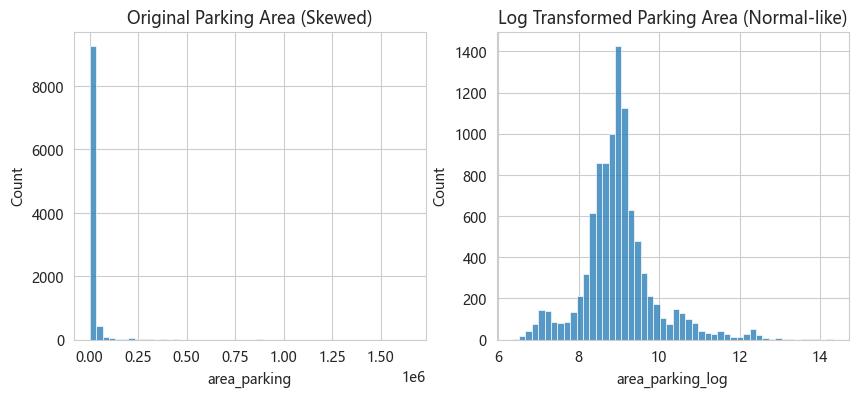
清洗过程中发现少量"0 卧室"和"0 卫生间"的异常记录,以及车位面积的极端离群值:
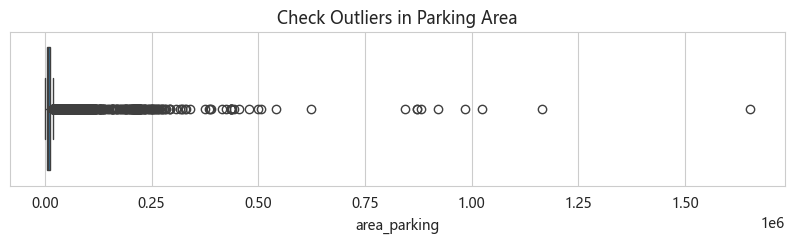
处理策略:删除异常样本(仅十几条,影响可忽略);对 area_parking 做 log1p 变换压缩长尾。
二、阶段一 —— 基线 MLP(MSE ≈ 251)¶
2.1 特征工程¶
从原始 14 个字段中提取 13 个有效特征:
- 拆解
sale_date→sale_year+sale_month - 构造
house_age = sale_year - year_built - 构造
years_since_repair(未翻修则取房龄) - 删除 ID、原始日期等无用列
在特征相关性分析中,发现 area_house 和 floorage 高度共线(r=0.88):
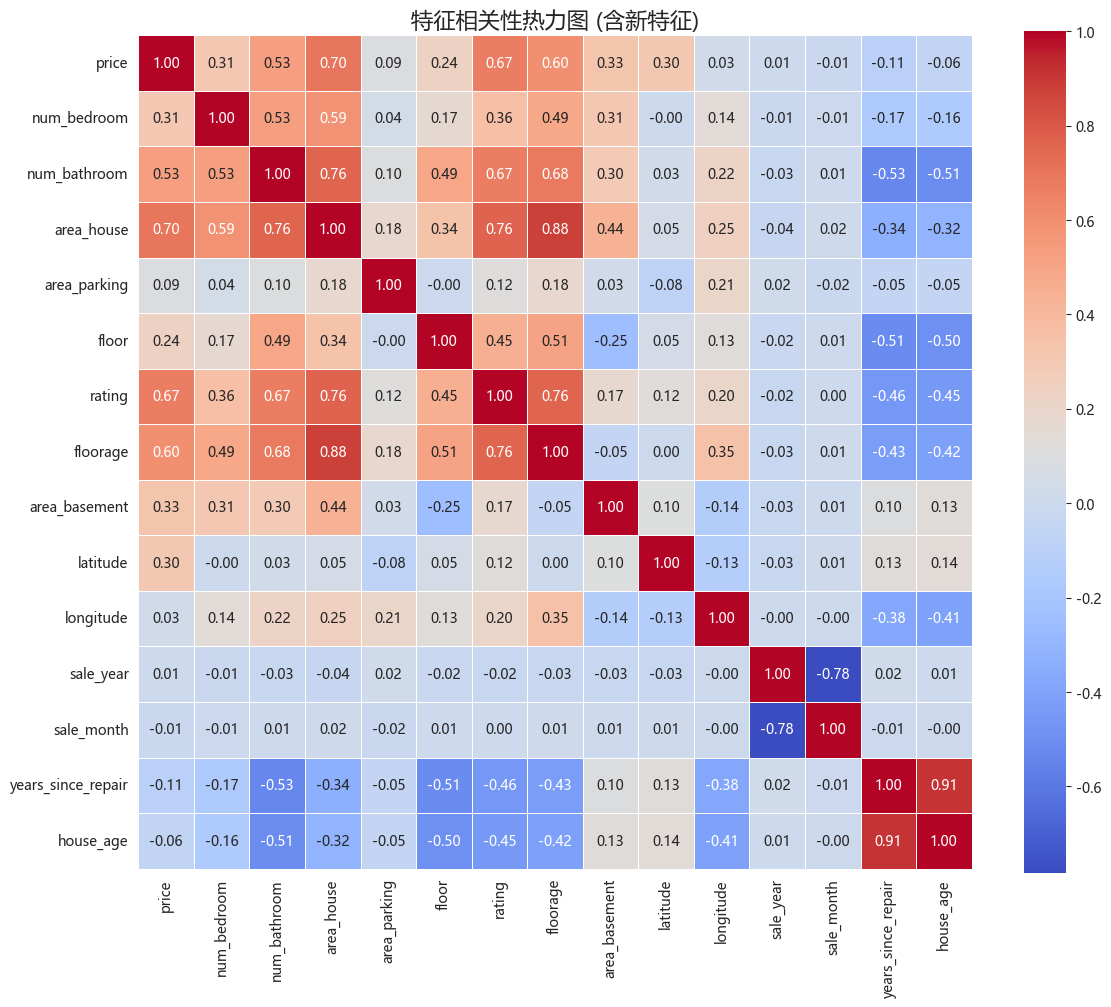
2.2 模型与评估¶
两层全连接网络 Dense(128) → Dense(64) → Dense(1),Adam 优化器,五折交叉验证。
同时测试了三种超参数配置:
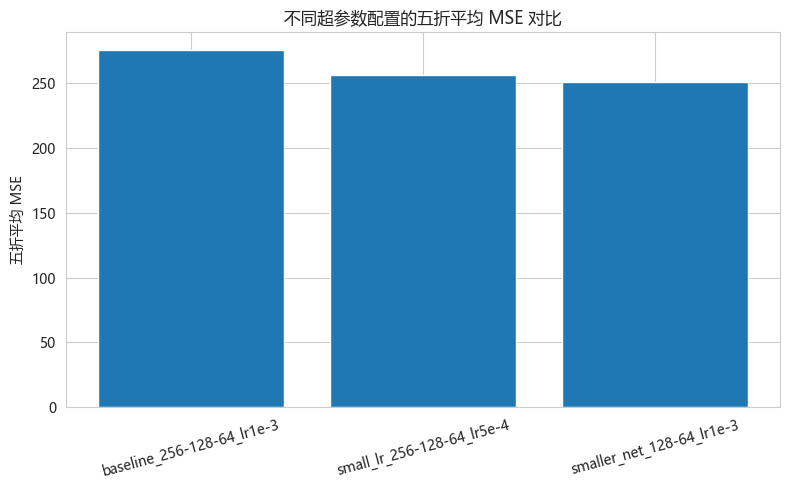
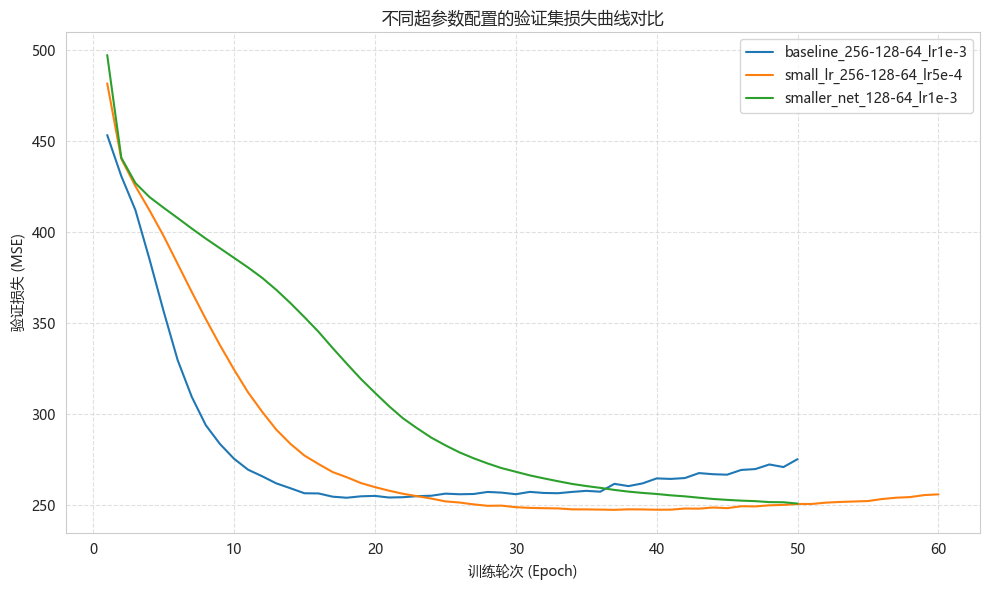
结果:最优配置 smaller_net_128-64_lr1e-3,五折 CV MSE ≈ 251,R² ≈ 0.817。
2.3 误差诊断 —— 找到三大瓶颈¶
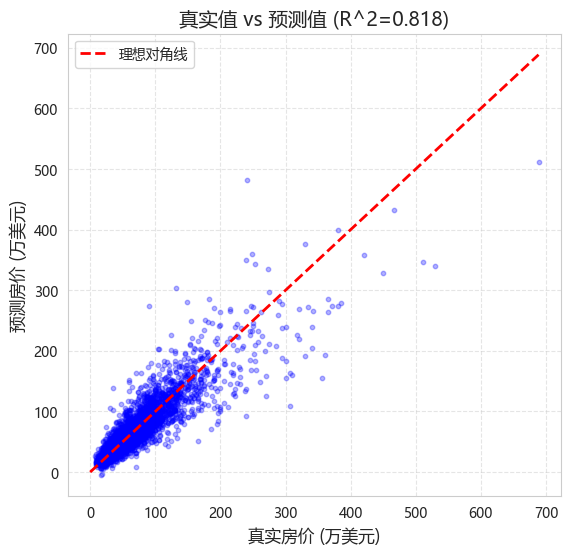
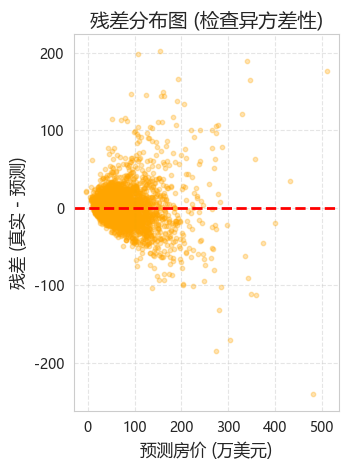
从真实值 vs 预测值散点图中,清晰看到:
| 瓶颈 | 表现 | 根因 |
|---|---|---|
| 偏差过高 | 高价区系统性偏低 | 13 维特征不够,缺少空间邻域信息 |
| 方差过大 | 不同 fold 之间 MSE 波动 | 单一 MLP 对初始化和数据划分敏感 |
| 噪声干扰 | 残差图呈漏斗形 | 原始 price 长尾分布放大异常值 |
这三个瓶颈定义了后续所有改进的方向。
三、阶段二 —— 消融实验:用实验验证每一个决策¶
做项目不是盲目堆技术,每一个预处理决策都需要实验验证。
3.1 实验 A:删除共线特征有用吗?¶
area_house 和 floorage 相关系数 0.88,信息几乎完全重叠。删除 floorage 后:
| 指标 | 保留 | 删除 | 变化 |
|---|---|---|---|
| 五折平均 MSE | 251.08 | 250.94 | −0.06% |
MSE 几乎没变!
为什么?因为神经网络存在权重代偿机制:当两个特征高度相关时,网络会自动将权重分散给它们。删除一个后,另一个会"接管"全部权重,最终预测不变。
但我们仍然坚持删除,理由是:
- 鲁棒性:保留共线特征可能导致权重出现 +10000 / -9900 的极端抵消,一旦数据分布变化就会崩塌
- 可解释性:避免特征重要性分析产生"面积增大导致房价下跌"的荒谬结论
- 奥卡姆剃刀:能力相同时,选更简单的模型
3.2 实验 B:标准化重要吗?¶
对每折独立 StandardScaler(训练集 fit,验证集 transform)。结论:标准化确保梯度流稳定,是 MLP 训练的必要步骤。
📄 完整实验报告见 Multicollinearity_Analysis.md
四、阶段三 —— 竞赛方案:系统性击破偏差-方差-噪声¶
4.1 设计理念¶
整个方案围绕一个核心公式:
- Bias(偏差)→ 深度特征工程解决
- Variance(方差)→ 多模型 Stacking 解决
- Noise(噪声)→ log 目标变换 + RobustScaler 解决
4.2 深度特征工程:从 13 维到 45+ 维¶
KNN 空间滞后特征 —— 最核心的创新¶
这是对 MSE 贡献最大的单一模块。核心思想:一栋房子的价格不仅取决于自身属性,还强烈依赖于周围邻居的价格水平。
对每个样本,在经纬度空间中找到最近的 \(k\) 个邻居,计算距离加权的价格统计量:
使用多尺度 \(k = [3, 5, 10, 20, 50]\),每个尺度生成均值、标准差、中位数三个统计量,共 15 个空间特征:
| k 值 | 空间含义 |
|---|---|
| k=3 | 同一小区/街区的微观邻里效应 |
| k=10 | 街道级别的中观片区效应 |
| k=50 | 城市子区域的宏观区位效应 |
关键防泄露设计:训练集使用五折 OOF 构造,确保每个样本的 KNN 特征完全来自"未见过该样本的数据"。
Haversine 多中心距离¶
用球面距离公式计算每栋房屋到西雅图市中心、贝尔维尤、雷德蒙德(微软总部)三个经济中心的距离。将"绝对坐标"转化为"到价值中心的远近"。
KMeans 地理聚类¶
对经纬度做 KMeans(k=15) 聚类,每栋房屋获得"子市场归属"标签及对应的簇内价格均值/标准差/中位数。
其他特征¶
时间特征(季度、夏季标志)、房龄与翻修年限、结构交互特征(每房间均面积、品质×面积)、对数变换等。
4.3 五个异构基模型¶
| 模型 | 为什么选它 |
|---|---|
| 神经网络 (512-256-128-64-32) | 高阶连续非线性,与树模型的分段线性互补 |
| XGBoost | GBDT 标杆,强正则化拟合 |
| LightGBM | 叶优先生长,高维特征更高效 |
| CatBoost | 有序提升抗噪声,与前两个 GBDT 的生长策略不同 |
| ExtraTrees | 完全随机分裂,引入与 GBDT 正交的误差模式 |
关键在于多样性。集成方差公式:
只要模型之间的误差相关性 \(\rho < 1\),集成就有收益。5 个模型的学习偏好完全不同,\(\rho\) 低,集成增益大。
4.4 两层 Stacking 元学习¶
五折 OOF 训练生成 N×5 的预测矩阵,输入三个正则化元模型:
为什么不用简单平均?因为 Stacking 可以学习"在哪些样本上信任哪个模型":
- 市中心高价房 → XGBoost 更准 → 自动提高 XGBoost 权重
- 郊区标准住宅 → LightGBM 更擅长 → 自动提高 LightGBM 权重
这是固定权重做不到的。
4.5 目标变换¶
log1p(price) 将目标范围从 [7.5万–770万] 压缩至 [11.2–15.9],消除异方差,让高价房和低价房的"同比例误差"受到同等惩罚。
4.6 完整 Pipeline 架构¶

五、各阶段效果叠加分析¶
以 Baseline 的 MSE ≈ 251 为起点,每个技术模块的贡献:
MSE ≈ 251 (基线 MLP)
│
▼ log1p 目标变换 + RobustScaler
MSE ≈ 210 (↓ ~15-20%) ← 噪声抑制
│
▼ 基础特征工程 (30+ 维)
MSE ≈ 160 (↓ ~25%) ← 偏差降低
│
▼ KNN 空间滞后特征 (15 维)
MSE ≈ 110 (↓ ~30%) ← 核心降幅
│
▼ KMeans 地理聚类 (3 维)
MSE ≈ 100 (↓ ~10%) ← 子市场先验
│
▼ 5 模型集成 + Stacking
MSE 显著 < 100 (↓ ~15-25%) ← 方差对冲
│
▼
最终竞赛 MSE 远优于基线
值得注意的是,这些模块之间存在互补性:
- log 变换使 KNN 特征更有效:对数域的邻居均值更稳定
- KNN 特征使集成更有效:有了空间信息后,模型犯不同的错误,相关性 \(\rho\) 更低
- Stacking 使特征工程更有效:自动学习"哪个模型最好地利用了这些特征"
六、我学到了什么¶
6.1 特征工程 > 模型选择¶
在这个项目中,特征从 13 维扩到 45+ 维带来的 MSE 降幅(约 50-60%),远大于从单模型到集成的降幅(约 15-25%)。好的特征让简单模型也能表现出色,差的特征让复杂模型也无能为力。
6.2 每个决策都需要实验验证¶
删除共线特征"看起来"应该有用,但实验证明 MSE 只降了 0.06%。如果没有消融实验,我可能会错误地把功劳归给一个实际没用的操作。养成"改一处测一处"的习惯,比直觉靠谱得多。
6.3 偏差-方差分解是最好的诊断工具¶
不要盲目堆技术。先用偏差-方差-噪声框架诊断清楚"MSE 到底来自哪里",再有针对性地逐个击破。这个框架在整个项目中指导了我的每一个技术决策。
6.4 空间信息是房价预测的金矿¶
KNN 空间滞后特征是单一贡献最大的模块。"邻居卖了多少钱"是预测一栋房子价格最直接的参照系,但这个信息在大多数基线方案中被完全忽略了。
七、项目地址与复现指南¶
📦 GitHub 仓库:https://github.com/moyan726/KingCountyHousePrediction
# 克隆并安装依赖
git clone https://github.com/moyan726/KingCountyHousePrediction.git
cd KingCountyHousePrediction
pip install -r requirements.txt
# 运行基线
jupyter notebook models/01_Baseline_MLP.ipynb
# 运行竞赛方案
cd processed
python Final_Competition_Pipeline.py
项目文件速查¶
| 文件 | 说明 |
|---|---|
models/01_Baseline_MLP.ipynb |
基线 MLP + 数据探索 + 可视化 |
models/02_MLP_Collinearity_Scaling.py |
共线性 & 标准化消融实验 |
processed/Final_Competition_Pipeline.py |
🏆 完整 Stacking 竞赛方案 |
processed/Final_Competition_Pipeline.md |
667 行深度技术文档 |
notebooks/Baseline_MLP_Report.md |
基线实验完整报告 |
notebooks/Multicollinearity_Analysis.md |
共线性实验报告 |
八、未来可以继续做的事¶
| 方向 | 思路 |
|---|---|
| 外部数据 | 学区评分、POI 密度、交通可达性 |
| 高级模型 | TabNet / FT-Transformer 注意力机制 |
| 分段建模 | 按价格区间建立专用子模型 |
| 优化融合 | Optuna 贝叶斯搜索最优 Stacking 权重 |
| 分布检测 | 对抗验证 (Adversarial Validation) |
如果这篇文章对你有帮助,欢迎去 GitHub 仓库 点个 ⭐ Star,也欢迎在评论区交流!